New algorithms for relational learning: where deep learning falls short of expectations
Feature learning makes relational data usable for machine learning, unlocking a vast trove of data with business potential for companies.
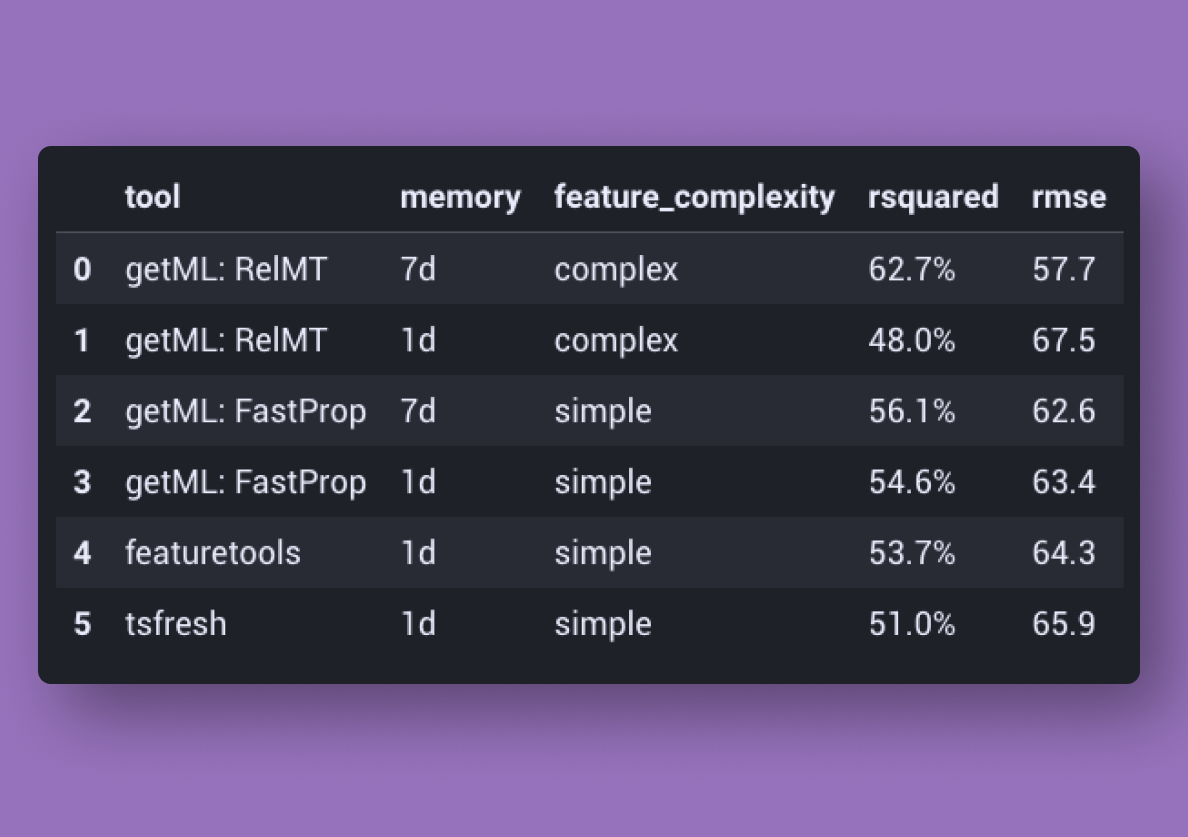
The idea of storing data in relational structures dates back to the 1970s. Today, relational data forms the backbone of every modern business. Corporate data accumulates in databases, playing a pivotal role in bridging the AI gap identified by decision-makers. However, despite the enthusiasm for innovation, extracting value from relational data with machine learning (ML) is currently only possible through significant effort. This challenge limits even large companies' access to machine learning and business applications with artificial intelligence (AI).